數(shù)據(jù)倉庫分層建設 架構(gòu)、方法與支撐體系
數(shù)據(jù)倉庫作為企業(yè)數(shù)據(jù)資產(chǎn)的核心載體,其分層建設是確保數(shù)據(jù)有序、高效、可管理的關(guān)鍵實踐。分層設計不僅能提升數(shù)據(jù)處理效率,更能保障數(shù)據(jù)質(zhì)量,支持復雜的分析需求,并適應業(yè)務的快速變化。
一、 為何要進行分層建設?
數(shù)據(jù)倉庫分層建設的核心價值在于解耦與復用,具體體現(xiàn)在:
- 清晰職責,降低復雜度:將龐大的數(shù)據(jù)處理流程分解為多個邏輯層次,每層職責明確(如原始數(shù)據(jù)接入、明細數(shù)據(jù)整合、公共維度匯總、應用數(shù)據(jù)服務),使開發(fā)和維護思路清晰,降低系統(tǒng)整體復雜性。
- 保障數(shù)據(jù)質(zhì)量與一致性:通過逐層的數(shù)據(jù)清洗、轉(zhuǎn)換和整合,確保數(shù)據(jù)從源頭到應用端的準確性、一致性和完整性。下層為上層提供“干凈”的數(shù)據(jù)原料,避免重復加工和口徑不一。
- 提升處理效率與資源利用率:分層后,公共的計算和聚合可以在中間層一次性完成,避免不同應用重復進行相同的基礎計算,節(jié)省計算和存儲資源。層次化的數(shù)據(jù)處理流程便于任務調(diào)度和性能優(yōu)化。
- 增強可擴展性與靈活性:當業(yè)務變化或新增數(shù)據(jù)源時,可以只針對受影響的層次進行修改或擴展,而不必重構(gòu)整個數(shù)據(jù)倉庫,降低了變更成本,提高了架構(gòu)的適應能力。
- 強化數(shù)據(jù)安全管理與血緣追溯:分層便于在不同層次實施差異化的數(shù)據(jù)安全策略(如敏感信息脫敏)。清晰的數(shù)據(jù)流向(血緣關(guān)系)也使得問題排查和影響分析變得容易。
二、 數(shù)據(jù)倉庫如何分層?
常見的經(jīng)典分層模型主要包含以下三層(可根據(jù)實際情況擴展):
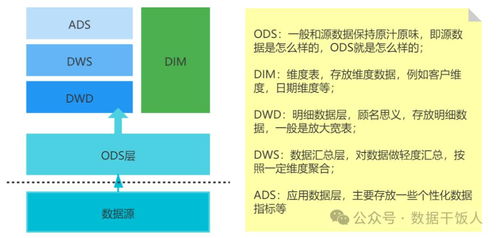
- 數(shù)據(jù)操作層(ODS, Operational Data Store):
- 定位:貼源層/緩沖層。
- 職責:直接接入來自各業(yè)務系統(tǒng)(如ERP、CRM)的原始數(shù)據(jù),盡可能保持原貌,完成初步的結(jié)構(gòu)化。主要承擔數(shù)據(jù)備份、短期歷史查詢和向下層提供原始數(shù)據(jù)的作用。
- 特點:數(shù)據(jù)粒度最細,更新頻率高,與源系統(tǒng)結(jié)構(gòu)相似度高。
- 數(shù)據(jù)倉庫層(DW, Data Warehouse):
- 定位:核心整合與建模層。此層可進一步細分為:
- 數(shù)據(jù)明細層(DWD, Data Warehouse Detail):對ODS層數(shù)據(jù)進行清洗、標準化、維度退化、業(yè)務過程拆分等,形成規(guī)范、一致的業(yè)務明細事實表。
- 數(shù)據(jù)中間層/服務層(DWS, Data Warehouse Service):基于DWD層,以主題域(如用戶、商品、交易)為導向,進行輕度匯總,形成跨業(yè)務的公共寬表或聚合模型,服務于通用的分析需求。
- 職責:整合企業(yè)全域數(shù)據(jù),構(gòu)建以維度建模為核心的企業(yè)級數(shù)據(jù)模型(星型/雪花模型),是數(shù)據(jù)加工和管理的核心區(qū)域。
- 特點:數(shù)據(jù)具有一致性、歷史性和主題性。
- 數(shù)據(jù)應用層(ADS, Application Data Service):
- 定位:個性化數(shù)據(jù)服務層。
- 職責:基于DW層數(shù)據(jù),根據(jù)具體的業(yè)務分析需求(如報表、數(shù)據(jù)產(chǎn)品、即席查詢、數(shù)據(jù)挖掘)進行高度匯總、指標計算或特定格式封裝,直接面向最終用戶或應用系統(tǒng)提供數(shù)據(jù)。
- 特點:數(shù)據(jù)高度聚合,查詢性能要求高,與業(yè)務需求緊密綁定。
三、 數(shù)據(jù)處理和存儲支持服務
分層架構(gòu)的有效運轉(zhuǎn),離不開底層強大的數(shù)據(jù)處理和存儲服務的支撐:
- 數(shù)據(jù)處理服務:
- ETL/ELT工具:如Apache NiFi, Talend, Informatica,或云廠商提供的DataWorks、Data Factory等,用于完成數(shù)據(jù)的抽取、清洗、轉(zhuǎn)換和加載。
- 大數(shù)據(jù)計算引擎:
- 批處理:Apache Hive, Spark SQL,用于處理海量歷史數(shù)據(jù)的ETL和聚合計算。
- 流處理:Apache Flink, Spark Streaming,用于實時或準實時地將數(shù)據(jù)從ODS層同步到DWD層,構(gòu)建實時數(shù)倉。
- 交互式查詢:Presto, Impala, ClickHouse,為ADS層或直接查詢DWS層提供低延遲的查詢服務。
- 任務調(diào)度與運維平臺:如Apache Airflow, DolphinScheduler,負責編排、調(diào)度和監(jiān)控跨層的ETL任務流,保障數(shù)據(jù)生產(chǎn)的穩(wěn)定性和時效性。
- 數(shù)據(jù)質(zhì)量與元數(shù)據(jù)管理:建立數(shù)據(jù)質(zhì)量稽核規(guī)則,監(jiān)控各層數(shù)據(jù)的完整性、準確性和及時性。通過元數(shù)據(jù)管理工具記錄數(shù)據(jù)血緣、資產(chǎn)目錄和業(yè)務含義。
- 數(shù)據(jù)存儲服務:
- ODS/DWD層存儲:通常使用成本較低、吞吐量高的分布式文件系統(tǒng)(如HDFS)或?qū)ο蟠鎯Γㄈ鏏WS S3, OSS),搭配列式存儲格式(如Parquet, ORC)以優(yōu)化壓縮和掃描性能。
- DWS/ADS層存儲:根據(jù)查詢模式選擇。對于復雜關(guān)聯(lián)查詢,可使用MPP數(shù)據(jù)庫(如Greenplum);對于高并發(fā)點查和聚合查詢,可使用分析型數(shù)據(jù)庫(如ClickHouse)或云數(shù)據(jù)倉庫(如Snowflake, Redshift, MaxCompute);對于即席查詢,可基于Hive或Presto查詢存儲在HDFS/S3上的數(shù)據(jù)。
- 實時數(shù)據(jù)存儲:對于流處理產(chǎn)生的實時聚合結(jié)果,常存入KV數(shù)據(jù)庫(如Redis)、時序數(shù)據(jù)庫或OLAP數(shù)據(jù)庫,以供實時應用調(diào)用。
數(shù)據(jù)倉庫的分層建設是一個系統(tǒng)性工程。明確的分層架構(gòu)是“藍圖”,而強大的數(shù)據(jù)處理與存儲服務則是實現(xiàn)這一藍圖的“工具和材料”。二者緊密結(jié)合,才能構(gòu)建出穩(wěn)定、高效、可擴展的企業(yè)級數(shù)據(jù)倉庫,真正釋放數(shù)據(jù)價值,驅(qū)動智能決策。
如若轉(zhuǎn)載,請注明出處:http://www.qyyfw.com.cn/product/57.html
更新時間:2026-01-10 18:06:38