十八款Hadoop工具,幫你高效馴服大數(shù)據(jù)
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,Hadoop作為處理海量數(shù)據(jù)的核心框架,其強(qiáng)大的分布式計(jì)算和存儲(chǔ)能力已成為企業(yè)駕馭大數(shù)據(jù)的基石。一個(gè)完整的“大數(shù)據(jù)生態(tài)系統(tǒng)”遠(yuǎn)不止于Hadoop本身,一系列圍繞其構(gòu)建的互補(bǔ)工具和服務(wù),共同構(gòu)成了強(qiáng)大、靈活且高效的數(shù)據(jù)處理與存儲(chǔ)支持體系。以下精選的十八款工具,將助您全方位地馴服大數(shù)據(jù)。
一、 數(shù)據(jù)存儲(chǔ)與管理層
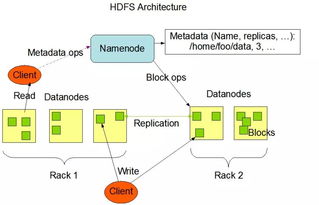
- HDFS (Hadoop Distributed File System): 基石中的基石,提供高容錯(cuò)、高吞吐量的數(shù)據(jù)存儲(chǔ)服務(wù),是Hadoop生態(tài)的存儲(chǔ)核心。
- HBase: 構(gòu)建于HDFS之上的分布式、面向列的NoSQL數(shù)據(jù)庫(kù),適合實(shí)時(shí)讀寫(xiě)和隨機(jī)訪(fǎng)問(wèn)超大規(guī)模稀疏數(shù)據(jù)集。
- Apache Kudu: 填補(bǔ)HDFS批量存儲(chǔ)與HBase低延遲存儲(chǔ)之間的空白,支持快速分析的同時(shí)也支持實(shí)時(shí)更新,適合時(shí)序數(shù)據(jù)等場(chǎng)景。
二、 資源調(diào)度與協(xié)調(diào)層
- YARN (Yet Another Resource Negotiator): Hadoop 2.0引入的核心組件,負(fù)責(zé)集群資源管理和作業(yè)調(diào)度,讓多種計(jì)算框架(如MapReduce, Spark)可以共享集群資源。
- Apache ZooKeeper: 分布式應(yīng)用的“協(xié)調(diào)員”,提供分布式鎖、配置維護(hù)、命名服務(wù)等,是HBase、Kafka等眾多分布式系統(tǒng)穩(wěn)定運(yùn)行的關(guān)鍵依賴(lài)。
三、 數(shù)據(jù)處理與計(jì)算引擎
- MapReduce: 經(jīng)典的批處理編程模型,適合處理超大規(guī)模數(shù)據(jù)集的離線(xiàn)計(jì)算任務(wù),穩(wěn)定性極高。
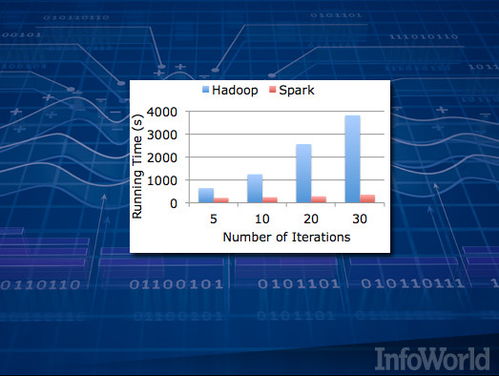
- Apache Spark: 基于內(nèi)存計(jì)算的統(tǒng)一分析引擎,在批處理、流處理、交互式查詢(xún)和機(jī)器學(xué)習(xí)方面表現(xiàn)卓越,速度遠(yuǎn)超MapReduce。
- Apache Flink: 真正的流處理優(yōu)先計(jì)算框架,提供高吞吐、低延遲、精確一次(exactly-once)的狀態(tài)計(jì)算,在實(shí)時(shí)處理領(lǐng)域優(yōu)勢(shì)明顯。
- Apache Tez: 旨在提升Hive、Pig等批處理作業(yè)執(zhí)行效率的通用計(jì)算框架,通過(guò)優(yōu)化任務(wù)執(zhí)行計(jì)劃來(lái)減少延遲。
四、 數(shù)據(jù)查詢(xún)與分析層
- Apache Hive: 基于Hadoop的數(shù)據(jù)倉(cāng)庫(kù)工具,提供類(lèi)SQL的查詢(xún)語(yǔ)言(HiveQL),將SQL語(yǔ)句轉(zhuǎn)換為MapReduce/Tez/Spark任務(wù),降低了大數(shù)據(jù)查詢(xún)門(mén)檻。
- Apache Impala: 專(zhuān)為HDFS和HBase設(shè)計(jì)的MPP(大規(guī)模并行處理)SQL查詢(xún)引擎,無(wú)需MapReduce,可直接提供低延遲的交互式SQL查詢(xún)。
- Presto: Facebook開(kāi)源的分布式SQL查詢(xún)引擎,支持跨多種數(shù)據(jù)源(如HDFS, Hive, Kafka, RDBMS)進(jìn)行快速交互式分析。
- Apache Pig: 提供高級(jí)腳本語(yǔ)言Pig Latin,簡(jiǎn)化了復(fù)雜MapReduce程序的開(kāi)發(fā),更適合數(shù)據(jù)流水線(xiàn)(ETL)任務(wù)。
五、 數(shù)據(jù)采集與集成層
- Apache Sqoop: 用于在Hadoop與結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)(如關(guān)系型數(shù)據(jù)庫(kù))之間高效傳輸批量數(shù)據(jù)的工具。
- Apache Flume: 一個(gè)高可用的、高可靠的分布式海量日志采集、聚合和傳輸系統(tǒng),非常適合將流式日志數(shù)據(jù)攝入HDFS。
- Apache Kafka: 分布式流數(shù)據(jù)平臺(tái),作為高吞吐量的消息隊(duì)列,是構(gòu)建實(shí)時(shí)數(shù)據(jù)管道和流應(yīng)用的核心,常作為流處理引擎(如Spark Streaming, Flink)的數(shù)據(jù)源。
六、 工作流調(diào)度與元數(shù)據(jù)管理
- Apache Oozie: Hadoop的工作流調(diào)度系統(tǒng),用于管理和協(xié)調(diào)復(fù)雜的多步驟數(shù)據(jù)處理作業(yè)(如包含Hive、Pig、Sqoop的任務(wù)序列)。
- Apache Atlas: 為Hadoop生態(tài)系統(tǒng)提供元數(shù)據(jù)管理與治理框架,支持?jǐn)?shù)據(jù)分類(lèi)、血緣追蹤、合規(guī)性審計(jì),是數(shù)據(jù)治理的關(guān)鍵工具。
###
這十八款工具各司其職,又緊密協(xié)作,共同構(gòu)建了一個(gè)從數(shù)據(jù)攝入、存儲(chǔ)、計(jì)算、分析到治理的完整閉環(huán)。選擇與組合這些工具時(shí),需根據(jù)具體的業(yè)務(wù)場(chǎng)景(如批處理優(yōu)先還是實(shí)時(shí)處理優(yōu)先)、技術(shù)棧熟悉度及團(tuán)隊(duì)運(yùn)維能力進(jìn)行權(quán)衡。熟練掌握這個(gè)強(qiáng)大的工具箱,您將能游刃有余地應(yīng)對(duì)大數(shù)據(jù)帶來(lái)的挑戰(zhàn),真正釋放數(shù)據(jù)的巨大價(jià)值。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.qyyfw.com.cn/product/49.html
更新時(shí)間:2026-01-10 02:02:47