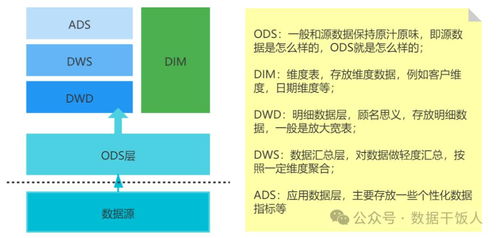
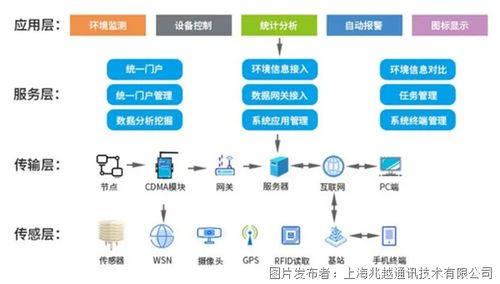
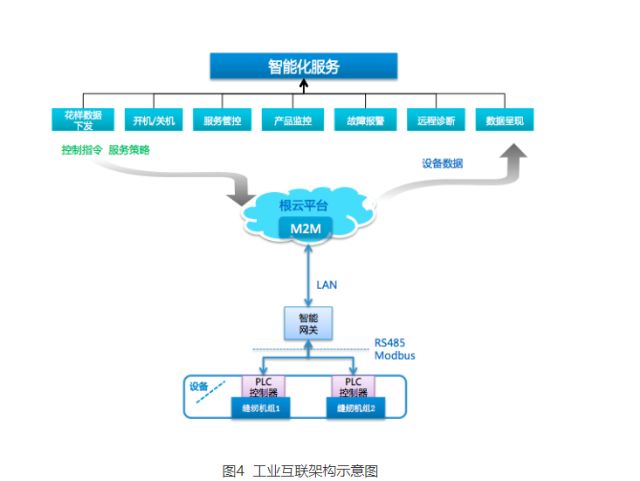
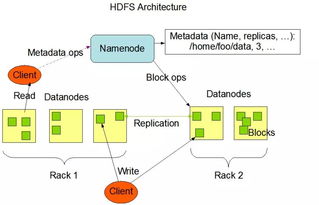
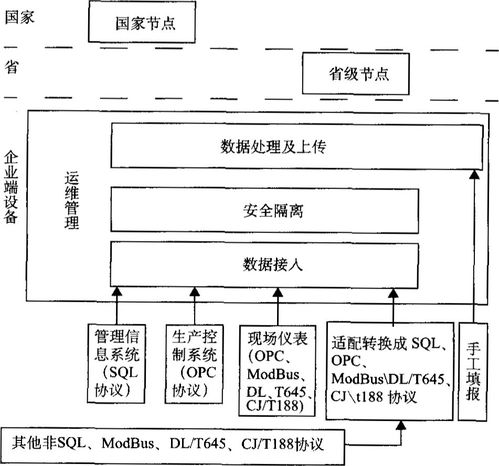
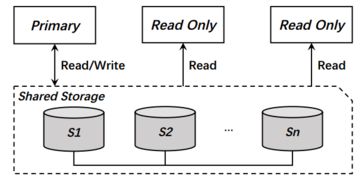
AI原生存儲 賦能大模型的數據基石,重塑數據處理與存儲支持服務
隨著人工智能,特別是大語言模型、多模態(tài)模型和生成式AI的飛速發(fā)展,數據已成為驅動這場智能革命的核心燃料。大模型訓練與推理對數據存儲提出了前所未有的挑戰(zhàn):海量非結構化數據(文本、圖像、音頻、視頻)、極高的讀寫吞吐量需求、數據預處理與標注的復雜性,以及對數據一致性、安全性和全生命周期管理的嚴苛要求。在此背景下,“AI原生存儲”應運而生,它并非簡單的硬件堆疊或存儲擴容,而是一種面向AI工作負載,深度融合數據處理與存儲支持服務的全新架構范式。
一、AI原生存儲的核心內涵:為智能而生
AI原生存儲的核心在于其“原生性”。它從設計之初便深度理解AI數據流水線的各個環(huán)節(jié)——從數據采集、清洗、標注、預處理,到模型訓練、驗證、部署和推理。它旨在打破傳統(tǒng)存儲系統(tǒng)與計算系統(tǒng)之間的壁壘,實現數據與算力的高效協(xié)同。其關鍵特征包括:
- 數據與算力緊耦合: 支持GPU/NPU直接訪問存儲數據(如通過GPUDirect Storage技術),大幅減少數據在CPU內存中的拷貝和搬運,將寶貴的計算資源從I/O瓶頸中解放出來,顯著提升訓練效率。
- 極致性能與擴展性: 針對AI負載中常見的“讀多寫少”、小文件海量、大文件順序讀寫等混合模式進行深度優(yōu)化。采用全閃存架構、分布式文件系統(tǒng)或對象存儲,提供線性擴展的帶寬和IOPS,輕松應對從PB到EB級的數據規(guī)模增長。
- 智能數據管理: 內嵌數據感知與管理能力。例如,自動識別“熱數據”(頻繁訪問的訓練集)與“冷數據”(歸檔的舊版本數據),實施智能分層存儲,優(yōu)化成本與性能的平衡。支持數據版本控制、快照和克隆,便于模型迭代與回滾。
- 集成化數據處理支持: 將部分數據預處理功能(如解碼、格式轉換、數據增強)下沉到存儲層或近存儲層執(zhí)行,實現“存算一體”或“近存計算”,進一步減少數據傳輸開銷,加速整體流水線。
二、提升大模型數據存儲能力的關鍵路徑
AI原生存儲如何具體提升大模型的能力?主要體現在以下幾個層面:
- 加速訓練周期: 通過提供超高吞吐量和低延遲的數據供給,確保成千上萬的GPU計算單元能夠持續(xù)“飽腹”工作,避免因數據I/O等待造成的算力閑置,從而將數月甚至數年的訓練時間大幅縮短。
- 支撐超大規(guī)模數據集: 大模型的性能提升嚴重依賴于數據規(guī)模與質量。AI原生存儲的橫向擴展能力,能夠無縫容納互聯網級的海量、多模態(tài)訓練數據,為模型“投喂”更豐富、更優(yōu)質的養(yǎng)分。
- 保障數據流水線敏捷性: 支持快速的數據湖/數據倉庫構建,方便數據科學家和工程師進行數據探索、實驗和管理。高效的數據版本管理和共享機制,使得團隊協(xié)作與模型復現更加順暢。
- 增強數據安全與合規(guī): 提供端到端的數據加密、訪問控制、審計日志以及數據脫敏功能,滿足企業(yè)在使用敏感數據訓練模型時的安全與隱私合規(guī)要求。
三、一體化數據處理與存儲支持服務:從基礎設施到價值實現
AI原生存儲的價值不止于“存儲”,更在于提供一體化的“數據處理與存儲支持服務”。這構成了一個完整的服務棧:
- 基礎設施即服務: 提供高性能、高可靠、彈性伸縮的存儲資源池,無論是本地部署、公有云還是混合云環(huán)境,都能以服務的形式靈活交付。
- 數據流水線即服務: 集成數據接入、轉換、標注、質量監(jiān)控等工具鏈,提供開箱即用的數據處理工作流模板,降低AI團隊的數據工程門檻。
- 性能優(yōu)化與調優(yōu)服務: 基于對AI工作負載的深度洞察,提供專業(yè)的存儲配置、數據布局和訪問模式優(yōu)化建議,確保系統(tǒng)始終處于最佳運行狀態(tài)。
- 運維管理與智能運維: 提供統(tǒng)一的監(jiān)控、告警、容量規(guī)劃和預測性維護能力。利用AI技術來管理AI存儲,實現故障自愈和性能自優(yōu)化。
四、展望未來:存儲與智能的深度融合
AI原生存儲將朝著更深度智能化的方向發(fā)展。存儲系統(tǒng)不僅能被動響應請求,更能主動理解AI應用的數據語義和訪問意圖,進行預測性數據預取和布局。以計算存儲(Computational Storage)為代表的存算融合技術將進一步發(fā)展,將部分模型推理或特定算子直接卸載到存儲設備中執(zhí)行,開創(chuàng)“數據在哪里,計算就在哪里”的新模式。
AI原生存儲是釋放大模型潛力的關鍵基礎設施。它通過重新定義存儲架構,提供深度融合的數據處理與存儲支持服務,正成為企業(yè)構建AI核心競爭力的數據基石,助力其在智能化浪潮中穩(wěn)健前行。
如若轉載,請注明出處:http://www.qyyfw.com.cn/product/47.html
更新時間:2026-01-10 04:44:28